
NewStarCTF2023_Week4_WP
NewStarCTF2023-系列:

Reverse
easy_js
js代码有obfuscator混淆
obfuscator解码
解码出来的代码修一修能跑
1 | function _0x4a2285(_0x2b5a00) { |
通过调试,整理代码,可以阅读出来,整体式一个rc4加密
_0x569454()为S盒生成函数, _0x221c90为rc4加密结果异或3
加密过程就是由_0x569454(‘admin’,‘123456’)生成S盒
然后rc4加密并异或3,最后base64得到’Cn8RHIJEVdvlrRESjETCscwQZdlhRfsRkWoHCTa0HcfLPg==’
由于rc4为对称加密,考虑直接调用_0x569454解密
直接用原来的js代码,在控制台里输入
document.write(_0x221c90(_0x569454('admin', '123456'), atob('Cn8RHIJEVdvlrRESjETCscwQZdlhRfsRkWoHCTa0HcfLPg==')));
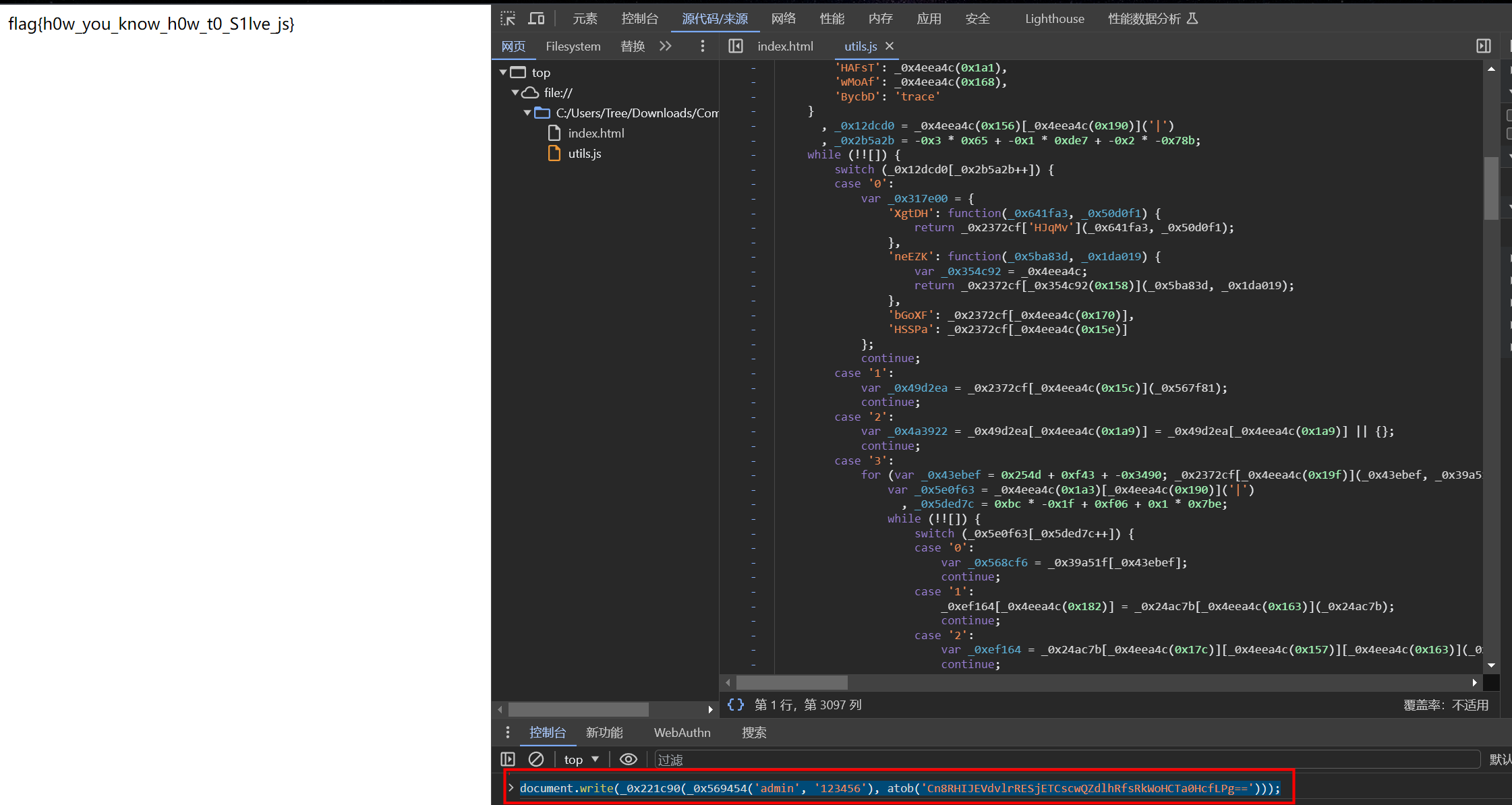
flag
flag{h0w_you_know_h0w_t0_S1lve_js}
茶
VM题,先把opcode dump出来
1 | addr = 0x61FC5C |
然后模拟一下VM过程
1 | def F1(a1,a2,a3): |
阅读一下可以得到F0-F6含义如下
1 | 0xF0 init |
结合栈空间的操作大致可以猜出来是tea,轮次40轮,两个位移都改成了5
看不出来也没关系 signsrch 也可以识别出来有个tea的常数delta
exp
1 |
|
flag
flag{WOWOW!Y0uG0tTh3F0urthPZGALAXY1eve1}
iwannarest
先用jadx 看看MainActivity
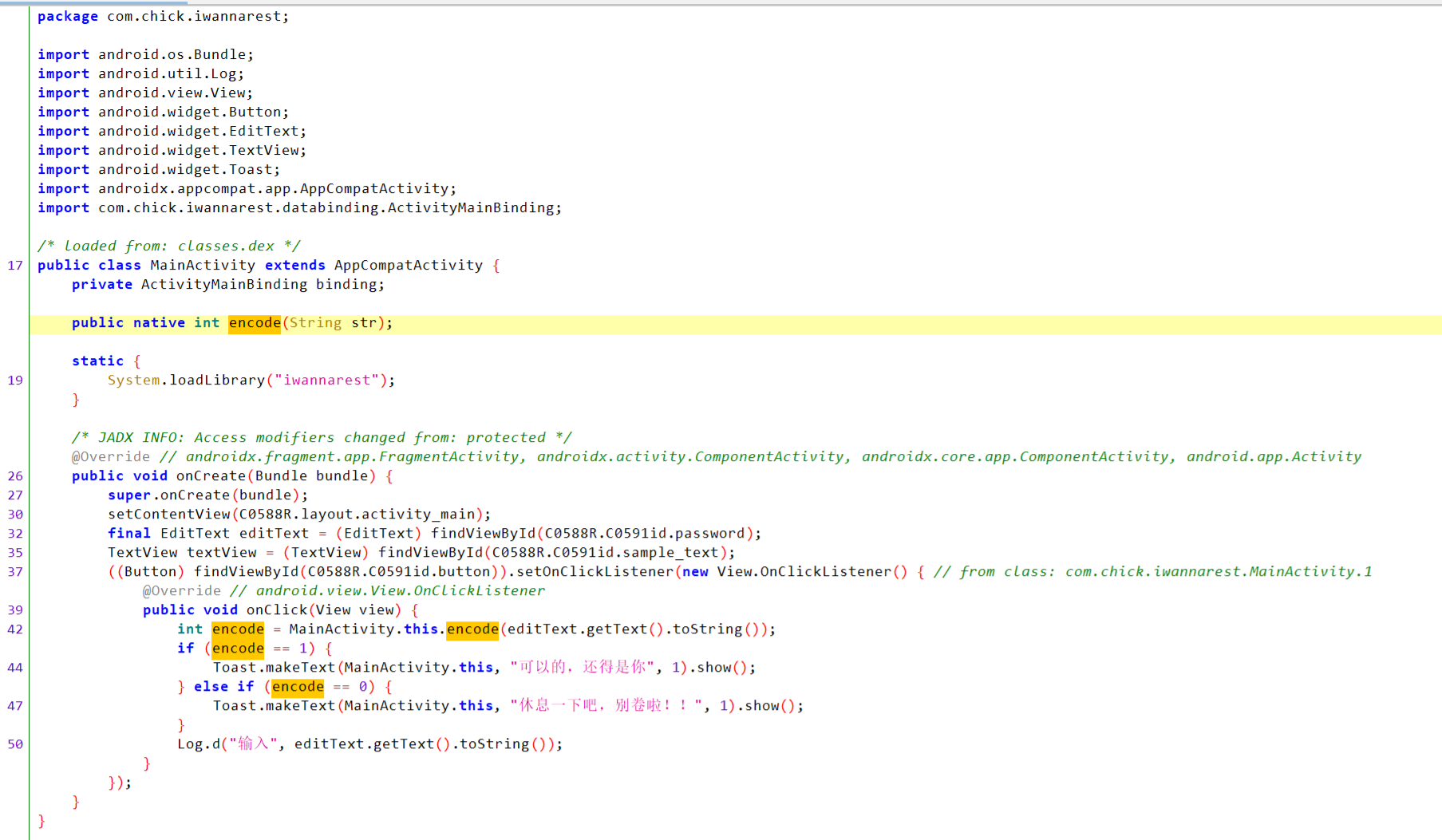
encode 函数在native层
进入\iwannarest\lib\x86_64 看看so文件
so文件里面没有encode但是函数较少,可以猜到zzz应该就是encode(后面看了官方wp才知道是采用了动态注册的方式去注册native层函数)
zzz应该是个xxtea,并且findcrypt插件也识别出来了
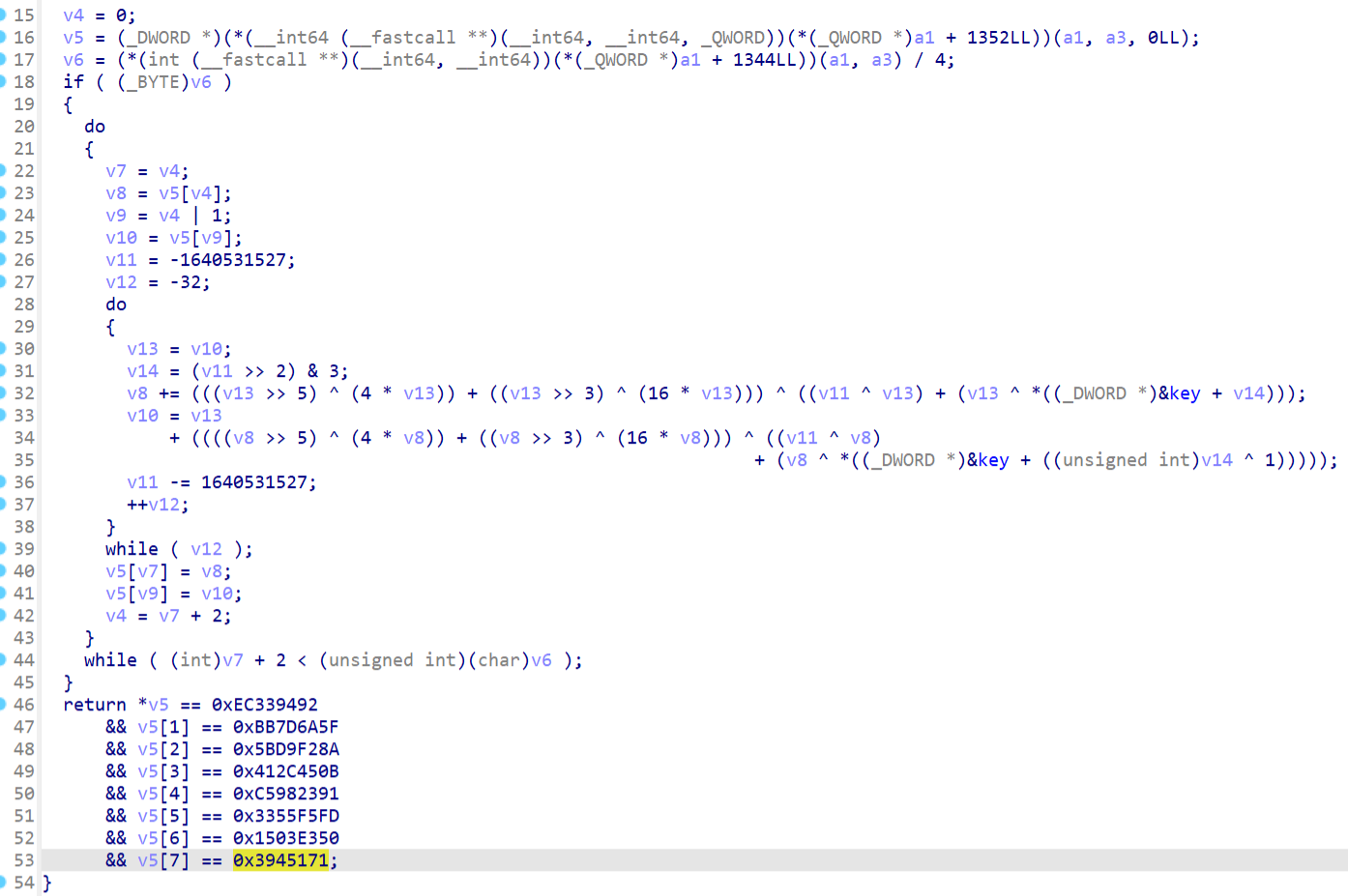
直接解应该解不出来,再观察发现init函数内修改了key,值是[1,1,4,5]
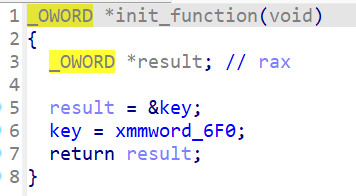
写脚本梭
exp
1 |
|
flag
flag{GDu7Il0v3uP1zl3tm3Gr@duate}
简单的跨栏
先看MainActivity
这部分应该是个反调试
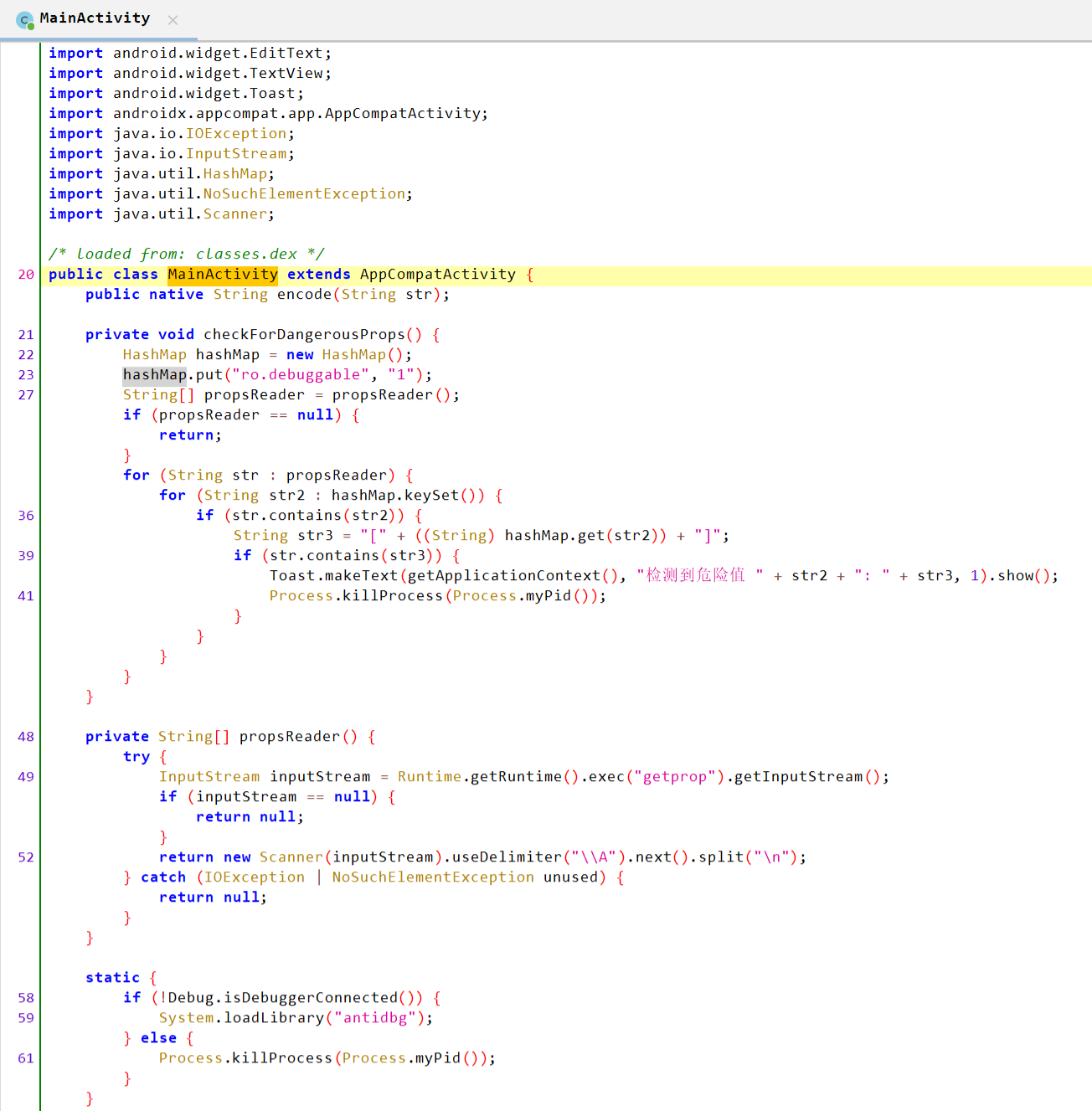
这部分生成S盒,交换,异或,一眼RC4

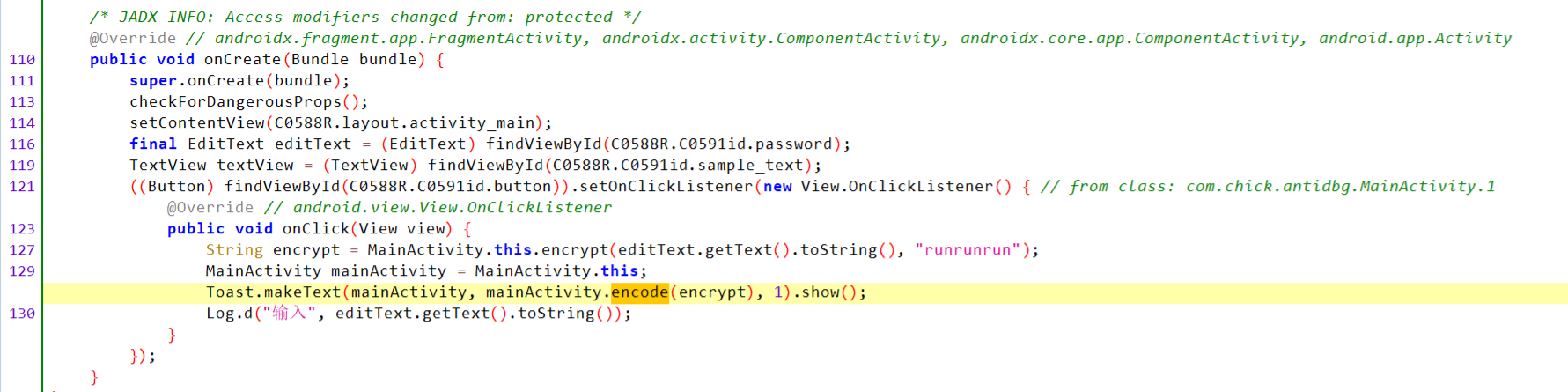
这部分先用key="runrunrun"RC4加密输入然后调用了native层的encode
去so中找找逻辑
在xxx中发现了密文
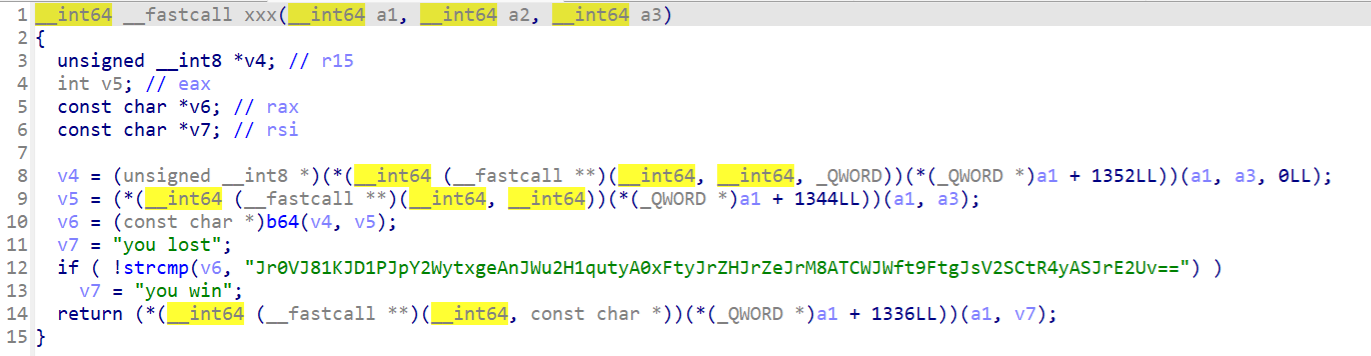
然后b64中明显的变表base64
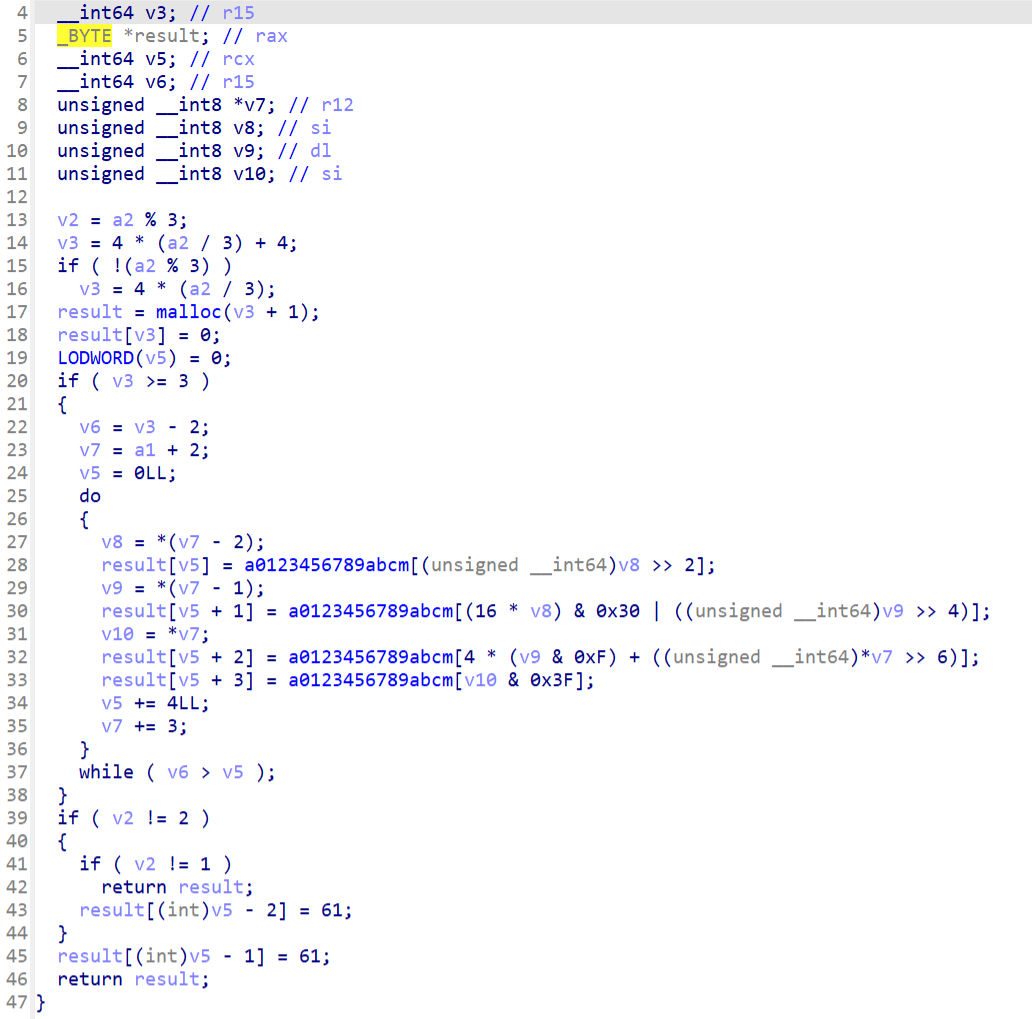
写脚本梭,对密文先解base64,然后用key='runrunrun'解rc4但是结果一直是错的
因为在java字符串传递到jni接口时,采用了GetStringUtfChars,这个函数会自动采用utf-8的解码格式。
我们需要将base64解密后的utf-8编码的数据转化为对应的Unicode编码
UTF-8编码,是Unicode的一种可变长度字符编码,是Unicode的一种实现方式,又称万国码;UTF8使用1~4字节为每个字符编码,相对于Unicode 固定的四字节长度,更节省存储空间。UTF-8字节长度与Unicode 码点对应关系如下:
一字节(0x00-0x7F)-> U+00~U+7F
二字节(0xC280-0xDFBF)-> U+80~U+7FF
三字节(0xE0A080-0xEFBFBF)-> U+800~U+FFFF
四字节(0xF0908080-0xF48FBFBF)-> U+10000~U+10FFFF
字符U+0000到U+007F(ASCII)被编码为字节0×00到0x7F(ASCIⅡ兼容)。这意味着只包含7位ASCIl字符的文件在ASCIⅡ和UTF-8两种编码方式下是一样的。
所有大于0x007F的字符被编码为一个有多个字节的串,每个字节都有标记位集,常用汉字基本上都被编码成三字节。
exp
1 | from Crypto.Cipher import ARC4 |
flag
flag{DED3D3DED3DE03DEBUG1sfunnyr1gh7??}







